The persistent ritual of null hypothesis significance testing

by Fabrizio Bernardi
Many empirical sociologists misuse statistical significance testing in their research.
At a conference, it is common to hear colleagues presenting their results with sentences like: “the coefficient is highly significant”, suggesting in this way that they have found an important result, or “the coefficient is not statistically significant”, implying that the coefficient is equal to 0. This impression is reinforced if one browses any major sociological journal. Many sociologists thus still engage in a practice that has been characterised as the ritual of Null Hypothesis Significance Testing (NHST).
In a nutshell, this ritual consists of the following: A researcher estimates a coefficient that expresses the effect of a variable X on a variable Y and computes its statistical significance p (note that in what follows I use the term ‘effect’ with no causal implication); if p is smaller than a conventional threshold (usually 0.05, sometimes 0.10), the researcher concludes that the coefficient is statistically significant and that there is an effect; conversely, if p is above the given threshold, the coefficient is statistically insignificant and the researcher concludes that there is no effect.
In this ritual, the size and sociological meaning of the coefficient and the uncertainty associated with the estimate are both ignored. The NHST is then a “yes-no” criterion to establish whether there is or is not an effect.
There are three main flaws associated with the ritual of the NHST.
First, researchers interpret a statistically significant coefficient as if it were also substantively significant, even when the effect is tiny in size and trivial in practice. This problem is more common when working with very large datasets where ultimately all estimates are statistically significant.
Second, researchers accept and write about implausibly large effects solely because they are statistically significant. This error is known as statistical significance filter or the “winner’s curse” and it is more common when working with small datasets.
Finally, researchers automatically interpret statistically insignificant coefficients as being equal to 0. Analogous to the previous flaw this could be labelled as the “loser’s curse.”
The problems associated with the ritual of the NHST are not new. Authoritative voices have warned against the ritual of NHST and confusion of statistical significance with substantive significance on many occasions. Unfortunately, sociologists, like their social science colleagues in neighbouring disciplines, tend to be diehard NHST practitioners.
A review for Europe
To better gauge the extent of the problem, myself and two colleagues reviewed all articles (N=356) published in the European Sociological Review (ESR) between 2000-2004 and 2010-2014 that used some type of significance testing. ESR is the leading journal for theoretically-driven empirical research in sociology in Europe. It has a high ranking in the Journal Citation Report by the Web of Science and an impact factor comparable or above other generalist journals such as Social Forces and Social Science Research.
The primary aim of our review was to determine whether ESR authors discuss the effect size of their findings and distinguish between substantive and statistical significance. We coded each article based on set of questions. The two most important questions were:
- Do the authors avoid interpreting a statistically insignificant coefficient as evidence of no effect?
- Do the authors discuss the substantive significance of the model coefficients?
The table below summarizes the main findings distinguishing the two time periods (2000-2004 and 2010-2014) considered in the review. The figures in the table refer to the percentage of articles that demonstrate good practices and qualified for a “Yes” to the questions above.
Proportion of articles demonstrating good practice
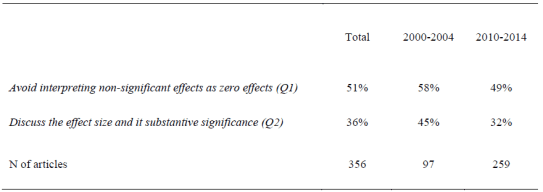
The table shows that just half of articles avoid the mechanical interpretation of a statistically insignificant coefficient as if it were equal to 0 (Q1) and only one in three comments explicitly on the effect size and the substantive significance of the estimates (Q2). This does not imply that the results published on ESR are trivial or lack substantive significance. Still, in two thirds of articles, authors neglect to discuss the effect size of their findings and are content to merely show that findings are “statistically significant.” Comparing the two time periods indicates that things have actually become worse over time.
What next?
We do not agree with those who propose to ban statistical significance altogether from research, as has recently happened in the journal Basic and Applied Social Psychology.
Our recommendation is to avoid mechanical use of the NHST, to use statistical significance as an indicator of the uncertainty in our estimates and to pay more attention to the size of effects and their substantive significance. This requires authors to identify a minimal and maximal substantively significant value for the effect under investigation, using prior knowledge and external information at hand. We label this procedure informed benchmarking of estimates.
Interested readers can find the more details on this procedure in our published article.
Changes in the editorial policy of major sociological journals could also discourage the use of the ritual of the NHST. In none of the major American generalist sociological journals such as American Journal of Sociology, American Sociological Review, Social Forces or Social Science Research does one find instructions for prospective authors that recommend a more careful use of statistical significance testing.
Concluding questions
Two questions emerge from our analysis of articles published in ESR. First, is US sociology different? Maybe, but I am not sure. A review similar to the one performed for ESR would certainly be valuable.
Second, why do sociologists (and social scientists more generally) still engage in this flawed practice, if its limitations were exposed long ago? Again I am not sure but I speculate that NHST is a powerful tool that simplifies and speeds up academic production, reducing each question to a dichotomous yes/no enquiry. It passes over the question of whether the size of estimate is trivial or implausibly large. It makes the life of researchers easier (whilst often lowering the quality of research output) and that may explain its resilience. It is certainly more difficult to publish a paper where we acknowledge that there is uncertainty in the results and we are not able to draw firm conclusions.
This does not excuse the lack of attention to effect size that we have documented in recent sociological research in Europe. In no cases do we completely lack the knowledge needed to develop some expectation of what a large or small effect might be.
Authors should always discuss the size of their estimates in the context of prior information on the phenomenon under study. In this way they would at least avoid the shame of writing a big story about a “statistically significant” coefficient that is actually trivial in terms of size. Similarly they would also reduce the risk of writing a big story on a “statistically significant” coefficient that is implausibly large when compared to the finding of previous studies on the same topic.
Fabrizio Bernardi is professor of Sociology at the European University Institute. This post summarizes findings from “Sing Me a Song With Social Significance”: The (mis)use of statistical significance testing,” in European Sociological Research.
Image: xkcd.

Pingback: The persistent ritual of null hypothesis significance testing » fabrizio bernardi